Data Quality Management and Performance Optimization for Enterprise-Scale ETL Pipelines in Modern Analytical Ecosystems
Article Sidebar
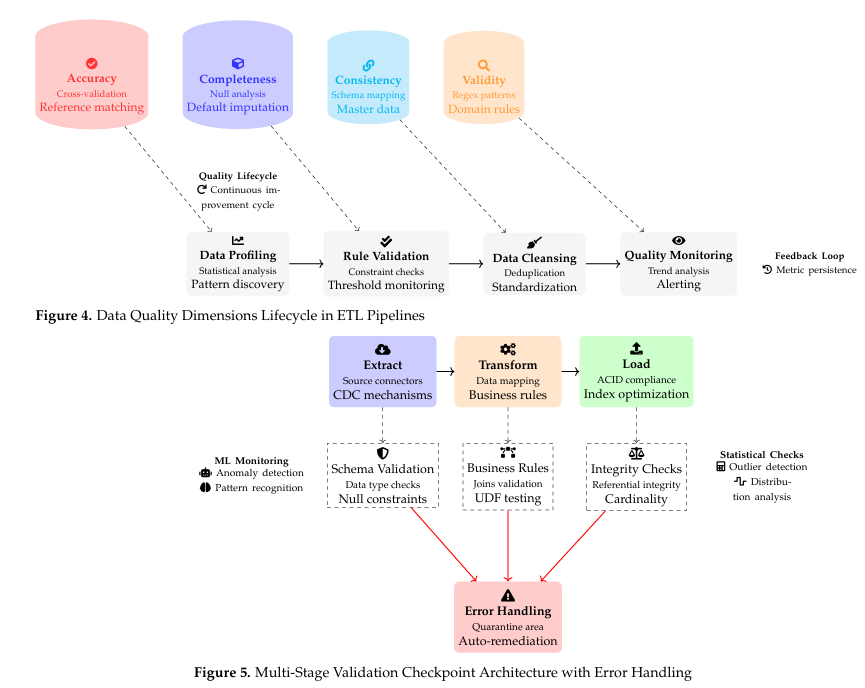
Main Article Content
Abstract
Data-driven business in the contemporary era depends upon solid ETL (Extract, Transform, Load) pipelines to consolidate and prepare data from various sources. With increasing volumes of data being dealt with by businesses and real-time analytics requirements, two criteria for success become paramount: the quality of data being delivered and the performance efficiency of the pipeline. This study provides a substantive theoretical examination of data quality management and performance enhancement in enterprise-sized ETL operations in today's analytical setting. It presents the design structure of modern-day ETL processes and how current design trends (for example, distributed processing and hybrid batch–streaming processes) enable scalability. Critical data quality factors—namely, accuracy, completeness, consistency, and timeliness—are discussed in the context of ETL processes, with an emphasis on techniques to uphold and guarantee these standards during sophisticated data transformations. The recurring theme is the tension between data quality and speed, as stringent validation and cleansing processes need to be completed without unduly delaying data delivery. At the same time, performance optimization techniques are discussed, from parallelism and resource scaling to algorithmic performance and pipeline orchestration optimizations that minimize latency and provide maximum throughput. The role of data governance and metadata management in long-term high performance and quality is also discussed, with a focus on lineage tracking and conformant practices. The prospects of ETL is discussed, including trends such as the move towards ELT, incorporation of streaming, and more advanced data management, and a glimpse into the prospects is given for innovation and challenges yet to come in this space.